
การออกแบบ database 1/2 [ Database the series ]
ใน Part นี้จะอธิบายถึง การออกแบบ relational database โดยเนื้อหาที่สำคัญจะเป็นเรื่อง Functional Dependencies , Design Guidelines กันนะครับบ
เริ่มที่เรื่องแรก การที่เราจะออกแบบ database ให้ดี เผื่อให้เวลาเราใช้งานแล้วไม่เกิดปัญหาต่างๆ เช่น ข้อมูลไม่ครบบ้าง , หายบ้าง หรือ ใช้งานยาก สิ่งที่จะเข้ามาช่วยก็คือ Design Guidelines นั่นเอง
Informal Design Guidelines for Relational Databases

การ design relational database การ จัดกลุ่ม attributes ให้อยู่ในรูปแบบความสัมพันธ์ที่ดี โดย relation schema จะมีอยู่ 2 level
- The logical level (user view)
- The storage level (base relation)
โดยในการออกแบบจะเกี่ยวข้องกับ base relation เป็นหลัก โดยการออกแบบชุดความสัมพันธ์ โดยมีเป้าหมายคือ การเก็บรักษาข้อมูล (information preservation) และ ความซ้ำซ้อนต่ำ (minimum redundancy)
GUIDELINE ที่ 1
ในแต่ละ tuple (row) ควรมีเพียง 1 entity หรือ relationship instance หรือก็คือ ใน 1 แถว attributes ในแถวนั้นควรจะนำเสนอเรื่องราวเดียวกัน (entity เดียวกัน) ไม่มีเรื่องอื่นมาเกี่ยวข้อง (entity อื่น) ถ้าจะมี จะต้องใช้ foriegn key reffer ไปหา table อื่น โดยควรแยก entity และ attributes ที่มีความสัมพันธ์ออกจากกันให้มากที่สุด
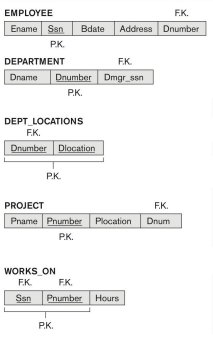
จากรูปจะเห็นได้ว่า Table EMPLOYEE มี attribute ที่เกี่ยวข้องกับ employee เท่านั้น และ relationship อื่นๆ เช่น DEPARTMENT จะถูกแยกออกมาเป็นอีก 1 table และใช้ Fk reffer หากันแทน
GUIDELINE ที่ 2
ไม่ควรมีการเก็บข้อมูลที่ซ้ำซ้อนกันเนื่องจากจะทำให้เกิดปัญหา
- เปลืองพื้นที่เก็บ
- เกิดปัญหา update anomalies
- Insertion anomalies
- Deletion anomalies
- Modification anomalies
anomalies คือ เหตุการณ์ที่ไม่ปกติโดยเกิดได้จากการ Insert , Delete , Update
ตัวอย่าง
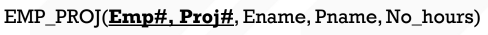
จาก relation นี้จะทำให้เกิด
Update Anomaly : เมื่อต้องการเปลี่ยนชื่อ project (Pname) ทำให้ต้องมาไล่เปลี่ยนในทุกๆ row
Insert Anomaly : ไม่สามารถเพิ่ม project ที่ไม่มี employee หรือ เพิ่ม employee ที่ไม่ถูก assign project ได้
Delete Anomaly : เมื่อ project ถูกลบ employee ที่ทำงานอยู่ใน project นั้นทั้งหมดก็จะถูกลบออกไปด้วย
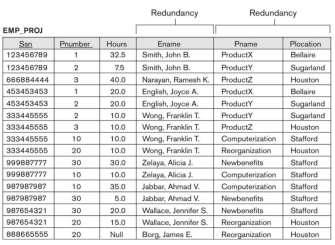
GUIDELINE ที่ 3
ในการออกแบบ relation คสรออกแบบให้ใน tuples มี NULL น้อยที่สุดเท่าที่จะเป็นไปได้ โดย attribute ไหนที่มีโอกาสเป็น NULL บ่อยๆ ควรที่จะถูกแยกออกมาเป็นอีก 1 table
GUIDELINE ที่ 4
ไม่ควรให้เกิด Spurious Tuples หรือก็คือ เมื่อมีการ Join ไม่ควรมีข้อมูลที่ไม่ถูกต้องเกิดขึ้น
ตัวอย่าง
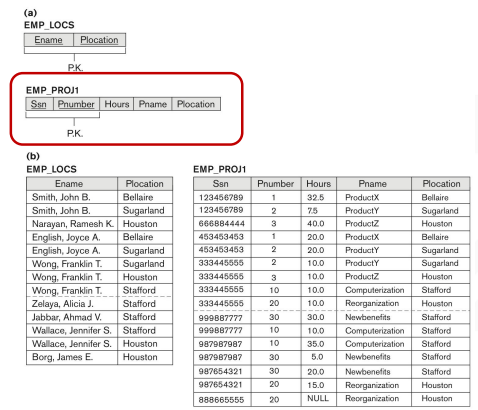
Join 2 table เข้าด้วยกัน คือ EMP_LOCS และ EMP_PROJ1 โดยใช้ Pnumber ในการ join
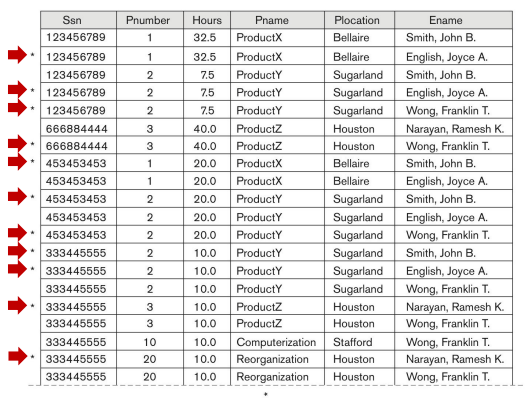
ผลที่ออกมาคือเกิดข้อมูลที่ไม่ถูกต้อง
Spurious Tuples
หรือก็คือ tuples ที่ข้อมูลที่ไม่ถูกต้อง ที่เกิดจากการ join ของ table โดยการที่จะป้องกันไม่ให้เกิด spurious tuple สามารถทำได้โดยการ decompositions
โดย
- ไม่เกิดข้อมูลที่ผิดผลาดหรือเสียข้อมูลจากการ join
- รักษา functional dependencies
Functional Dependencies
Functional dependencies หรือ FDs เป็นตัวที่ใช้ในการตรวจสอบว่า relational ที่ออกแบบนั้นดีหรือเปล่า และ เป็นตัวในการตัดสินว่าที่ออกแบบอยู่ใน normal form รูปแบบที่เท่าไหร่
โดย กลุ่มของ attribute X functionally determines กลุ่มของ attribute Y ถ้า ค่าของ X สามารถกำหนดค่า Y ได้ เช่น
SSN determines ENAME (รู้ SSN -> รู้ ENAME)
หรือ เมื่อก่อนจะเรียกว่า ENAME depend on SSN
โดยที่ FD คือสมบัติของ attribute ที่อยู่ใน schema นั้นๆ
ถ้า K เป็น key ของ R -> K จะ determines ทุกๆ attribute ใน R
จบไปแล้วสำหรับเนื้อหาใน part นี้นะครับ โดยในเรื่องนี้จะถูกแบ่งออกเป็น 2 part หวังว่าจะมีประโยชน์กับคนที่ได้เข้ามาอ่านนะครับ ขอบคุณทุกคนที่อ่านจนจบนะครับ สำหรับเนื้อหาต่อจากนี้สามารถติดตาม Part ต่อได้เลย
Credit
Illustration by Icons 8 from Ouch!

